
机器学习实战之训练模型-深入分析线性回归
线性回归模型就是对输入特征加权求和,再加上一个我们称为偏置项(截距)的常数,以此进行预测。它反映的是每一个特征对因变量的影响方向(\(θ\)值的正负)和影响力(\(θ\)的绝对值大小)。
1. 模型说明
线性回归公式如下:
\(\hat{y}=θ_0+θ_1x_1+θ_2x_2+…+θ_nx_n\)
- \(\hat{y}\)是预测值
- \(n\)是特征的数量
- \(x_i\)是第i个特征值
- \(θ_j\)是第j个模型参数(包括偏置项\(θ_0\)以及特征权重\(θ_1\),\(θ_2\),…,\(θ_n\))
我也给出一个向量化的线性回归公式,看得明白的人就看一下,看不明白的人当作看明白就可以了。
\(\hat{y} = h_θ(X) = θ^T·X\)
- \(θ\)是模型的参数向量(列向量)
- \(θ^T\)是\(θ\)的转置向量(行向量)
- \(X\)是实例特征向量(矩阵,包括\(x_0\)到\(x_n\),\(x_0\)永远为1)
- \(h_θ\)是使用模型参数\(θ\)的假设函数
- \(θ^T·X\)是\(θ^T\)和\(X\)的点积
在数学中,点积是一种接受两个等长的数字序列(通常是坐标向量)、返回单个数字的代数运算,先对两个数字序列中的每组对应元素求积,再对所有积求和,结果即为点积
2. 成本函数
我们如何训练模型呢,我们需要知道如何衡量模型对训练数据的拟合程度的好与坏,回归模型最常见的性能指标(成本函数)是均方误差MSE,我们寻找一个,使得MSE最小化。
\(MSE=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\)
为了得到使得成本函数MSE最小值的,有一个闭式解方法,就是一个直接得出结论的数学方差,叫做标准方程。
\(\hat{θ} = (X^T·X)^{-1}·X^T·y\)
- \(\hat{θ}\)是使得成本函数最小的\(θ\)值
- \(y\)是包含\(y^{(1)}\)到\(y^{(n)}\)的目标值向量(因变量向量)
3. 标准方程Python实现
3.1 生成线性数据来进行模型拟合
我们通过\(y=4+3x_0+ε\)公式来生成模拟数(\(ε\)为高斯噪声)。
import numpy as np import matplotlib.pyplot as plt X = 2 * np.random.rand(100,1)#生产100个1维随机数 y = 4 + 3 * X +np.random.randn(100,1)#生成满足y=4+3x的数据,加入一些随机值
我们看看部分的X,如下图
我们看看部分的y,如下图
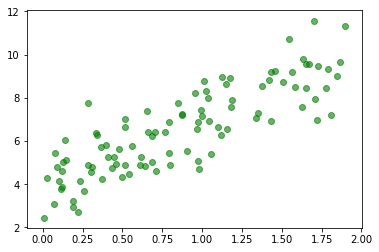
我们把随机生成的X和y画出来看看。
3.2 标准方程求解
接下来我们用标准方程直接求解\(\hatθ\)。使用NumPy的线性代数模块np.linalg中的inv()函数对矩阵求逆,并用dot()方法计算矩阵的内积(点积)。
X2 = np.c_[np.ones((100,1)),X]#增加100个1的1维向量和X组合在一起,变成两个特征的向量,请大牛解析下面一行代码 theta_best = np.linalg.inv(X2.T.dot(X2)).dot(X2.T).dot(y)
X2是这样的:
我们直接打印theta_best 出来,它就是我们通过这个公式\(y=4+3x_0+ε\) 模拟的数据的\(\hat{θ}\)的结果:
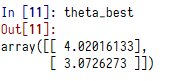
我们期待的是\(θ_0=4\),\(θ_1=3\),我们得到的是\(θ_0=4.02\),\(θ_1=3.07\),非常接近,噪声的存在使得我们不可能完成还原出原本的函数。
我们用我们得到的参数来进行预测
X_new = np.array([[0],[2]]) #x=0和x=2进行预测,X_new为列向量 X_new_b = np.c_[np.ones((2,1)),X_new] #X_new列向量增加一列常量为1的向量 y_predict = X_new_b.dot(theta_best) y_predict
结果如下:

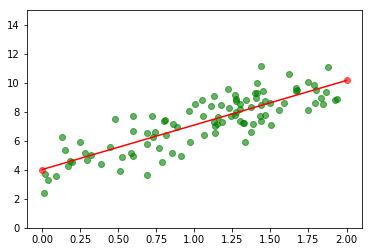
我们把原始数据和预测数据都画到同一个图上,也把模拟得到的回归曲线画出来
plt.scatter(X,y,c='green', alpha=0.6) plt.scatter(X_new,y_predict,c='red', alpha=0.6) plt.plot(X_new,y_predict,c='red') plt.axis([-0.1,2.1,0,15]) #设置坐标轴的X和Y的最大值和最小值 plt.show()
3.3 Scikit-Learn实现
我们用Scikit-Learn的同样可以实现。
from sklearn.linear_model import LinearRegression reg = LinearRegression() reg.fit(X,y)#sklearn的x不需要增加一个值为1的特征向量,默认回归是包含截距的 reg.intercept_,reg.coef_ reg.predict(X_new)
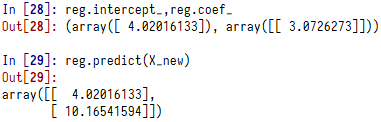
模型参数的拟合值和对X_new的预测值是一样的。
3.4 statsmodels实现
我们用statsmodels库再做一次
import statsmodels.api as sm x1 = sm.add_constant(X) #X是一维,通过一个简单的函数,就可以增加一个值为1的特征向量,实现了X2 = np.c_[np.ones((100,1)),X] models = sm.OLS(y,x1) rs = models.fit() print(rs.summary())
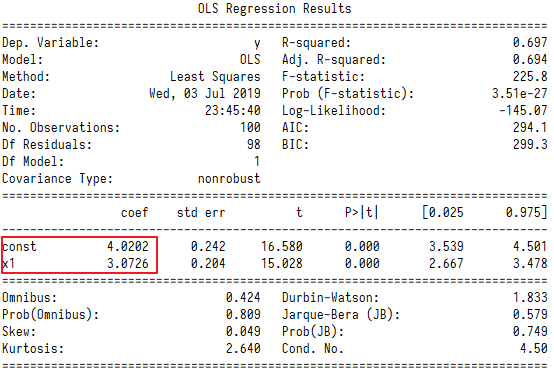
并且statsmodels给出了更详细的分析结果。
用statsmodels进行预测,注意rs.predict()里面的参数是包括常量1的列向量。
rs.predict(X_new_b)
结果是
array([ 4.02016133, 10.16541594])
和我们其他的方法是一样的。
3.5 梯度下降实现
这里再提供一个梯度下降算法达到统一的目标。梯度下降算法的原理就不解释了,具体请点击这里链接。
eta = 0.1
n_iterations =1000
m = 100
theta = np.random.randn(2,1)
for iteration in range(n_iterations):
gradients = 2/m * X2.T.dot(X2.dot(theta)-y)
theta = theta - eta * gradients
theta
结果是一样的。
如果需要了解其他的线性回归的性能评估方法,请看《回归分析及预测性能评估(通过python的scikit-learn实现)》

