
回归分析及预测性能评估(通过python的scikit-learn实现)
预测型数据分析有很多很多种分析的类型,回归、分类和聚类是预测型数据分析的几种主要的类型。
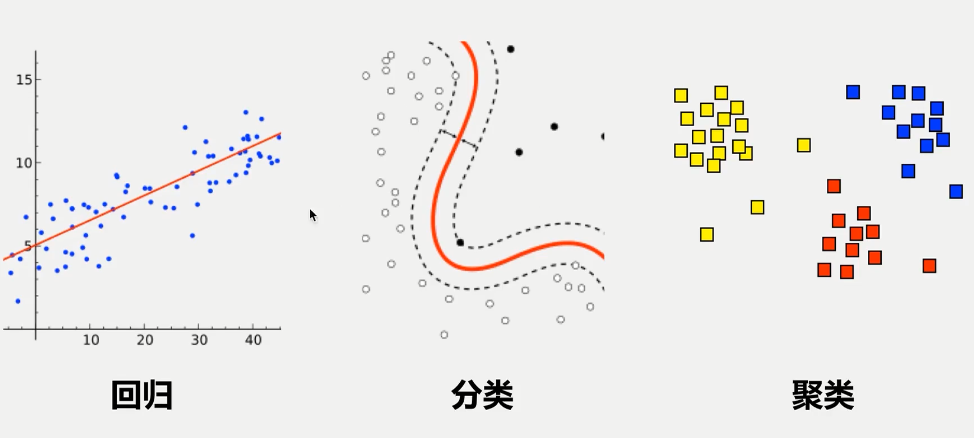
回归和分类属于监督型学习,回归分析在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量(变量组)来预测研究者感兴趣的变量(因变量),可以帮助了解在只有一个自变量变化时因变量的变化量。而分类的和回归非常类似,分类的因变量是离散的,用离散的数值类进行分类。比如说我们有一些已知植物的属性(分类、叶长、叶宽、花瓣数),建立分类回归模型,通过新的一个样本的叶长、叶宽、花瓣数去预测这个样本的分类。
下面我们说说回归分析
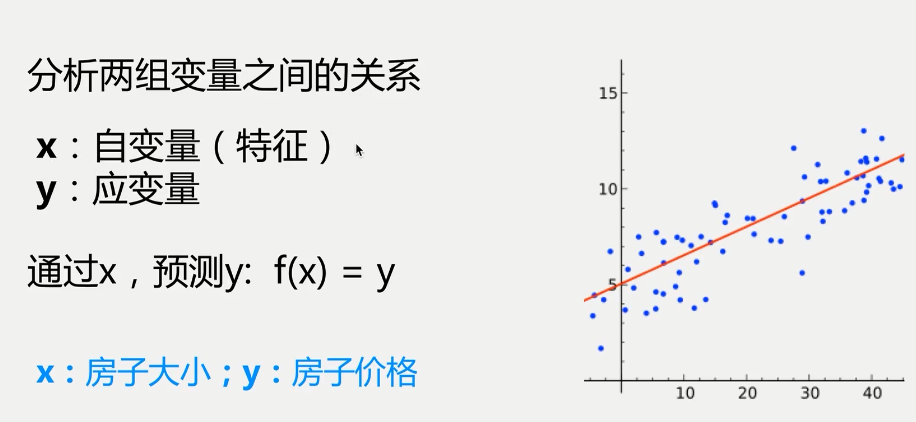
x自变量也叫特征,可以是一维或者多维,y是因变量,我们通过已知的x和y,建立一个y和x之间的函数来评估x和y之间的关系,进行用新的x去预测y。
关于回归分析及通过excel进行回归分析,可以参考我的这篇文章《利用EXCEL函数LINEST进行统计学中的回归分析》,在我的另一篇文章《传统IT应用如何拥抱大数据?谈python大数据的应用落地方法》也有用Python的statsmodels模块如何实现回归分析的应用。
Python中实现线性回归的主流包是scikit-learn,下面我们一步一步来通过scikit-learn实现回归分析和预测性能的评估。
首先我们来了解一下核心代码
from sklearn import linear_model #引入python的sklearn模块 lm = linear_model.LinearRegression() #创建一个线性回归模型 model = lm.fit(X,y)#对回归模型进行拟合
下面我们从头开始一个完整的回归分析、预测和预测性能评估。
1 加载数据(鸢尾属植物数据集)
mport pandas
iris = pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']
我们通过下面的代码查看数据
iris.sample(10)
数据如下:
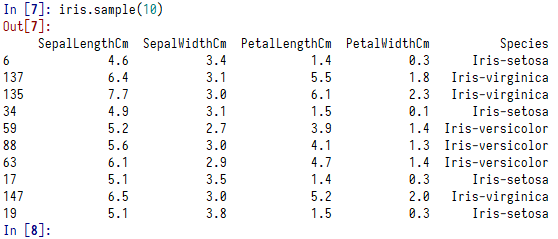
数据总共有五列,分别为:
- epalLengthCm:花萼长度
- SepalWidthCm:花萼宽度
- PetalLengthCm:花瓣长度
- PetalWidthCm:花瓣宽度
- Species:分类( Iris-setosa、Iris-virginica、Iris-versicolour)
2 探索数据
如果你想知道Species分类有多少个分类,可以通过下面的代码查看,drop不会删除原来的数据集。
iris.drop_duplicates(['Species'])
如下:

接下来我们引入seaborn先探索一下数据。
import seaborn as sns sns.regplot(x='PetalLengthCm',y='PetalWidthCm',data=iris)
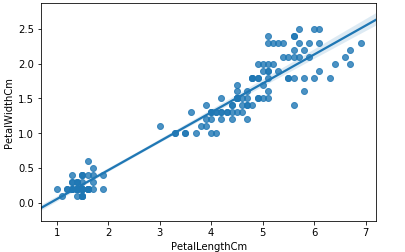
可以看到花瓣长度和花瓣宽度有很好的线性关系,并且seaborn已经自动把这两个变量通过线性拟合出来一条直线了。
3 回归拟合
lm = linear_model.LinearRegression() #创建回归模型 features = ['PetalLengthCm'] #定义特征值,就是选项自变量,可以多个,多个的写法features = ['a','b'] X = iris[features] #从数据集中选取特征值数据 y = iris['PetalWidthCm'] #定义因变量 model = lm.fit(X,y) #y=a+bX进行拟合 print(model.intercept_,model.coef_) #输出截距a和特征系数b
最后一句输出以下内容:
-0.366514045217 [ 0.41641913]
就是说我们可以把我们拟合的函数写成:
y=-0.3665+0.4164X
比如,如果我们知道一个X值为3.5,我们通过这个公式计算出y值。
model.predict(3.5)
返回
Out[23]: array([ 1.09095292])
接下来我们把特性引进多个进行尝试。
lm = linear_model.LinearRegression() features = ['PetalLengthCm','SepalLengthCm'] X = iris[features] y = iris['PetalWidthCm'] model = lm.fit(X,y) print(model.intercept_,model.coef_)
结果返回:
-0.013852011013 [ 0.44992999 -0.08190841]
第一个是截距,第二个是一个列表,列表里面的两个数分别是两个特征的系数。
预测
model.predict([[1,3]])

预测性能的评估,我们需要一个训练集和一个对应的测试集,如果我们对刚刚的iris数据集全部数据进行拟合回归,做的误差分析依然是在同一个数据集上,实际上我们并没有得到更多的关于这个拟合模型的一个估计性能,因为我们并没有把我们预测模型去预测未知的东西。
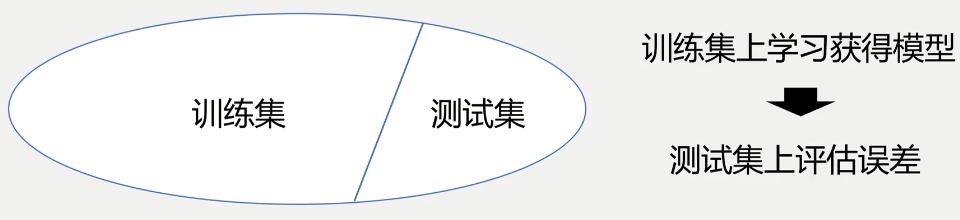
一般我们在机器学习中最核心的预测性能估计,是把样本划分为两个部分,一部分用于训练的训练集,一部分用于测试的测试集。我们只在训练集上进行我们的模型学习,再用测试集对得到的模型进行评估。一般训练集和测试集的比例是8:2,然后随机划分很多次,比如10次100次,再整体看看我们模型的性能,比如取性能的平均值。但随机划分数据集的这种方法,还是不能保证每一个样本被测试过。
交叉检验
接下来介绍一种更常用的预测性能评估的方法,叫交叉检验。它把样本分成指定的份数,比如下图的5份,这5份的数据都是随机的,但确定下来就是固定的。我们用这5份交替的进行交叉检验。
比如第一轮,我们拿4份进行训练,这样我们可以得到一个最好的模型,然后我们拿这个模型去对那剩余的1份数据集进行测试,看在测试集上我们预测的Y和真实的Y的误差有多大,第一轮我们就可以得到一个误差数据。
第二轮,我们从5份的数据子集中拿另外的4份再重复上面的操作,第二轮我们又可以得到一个误差数据。
如此类推,我们做完5轮。如果你的数据分成更多发份数,那就做更多的交叉检验次数即可。
这一套方法在数据分析和研究中是非常非常常用的,也是用来挑选哪个模型性能更好的最常用的方法。

接下来我们在Python中用scikit-learn来实现预测模型的建立和进行检查检验。
回归的性能评估常用的打分函数,一个是绝对误差,一个是均方误差,很明显这两个公式返回的值都是大于0的数。两个公式的结果值越小,表示预测值和实际值越接近,预测性能越好。

在scikit-learn中实现性能评估是非常简单方便的。
from sklearn.model_selection import cross_val_score cross_val_score(lm,X,y,cv=5,scoring='neg_mean_absolute_error')
lm就是我们上面建立的模型,cv=5是指样本的划分份数,你可以设置为10或者更大都可以,scoring就是我们的打分函数。

- 需要注意的是在sklearn中cross_val_score的打分函数中返回的是MAE、MSE的负数,所以在cross_val_score中返回的MAE和MSE是负数,这个值越大性能越好。
- 但我还是看正数舒服一点,那么我们就在cross_val_score函数前面增加一个负号,这样cross_val_score得到的值就是和我们上面MAE和MSE公式的值是一直的,越小越好。
- cv=5,进行了5轮评估,cross_val_score返回一个数组,分别是5轮的性能得分,我们可以计算它们的平均值作为最终的得分。
接下来我们进行一次完整的评估。
第一次
我们用建立一个PetalLengthCm作为自变量X、PetalWidthCm作为因变量y的回归模型,看看它的性能。
lm = linear_model.LinearRegression() features = ['PetalLengthCm'] X = iris[features] y = iris['PetalWidthCm'] model = lm.fit(X,y) score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error')) print(score)
socre结果为:0.0454809790262
我们可以把样本尝试划分为10份,看看效果如何。
score = numpy.mean(-cross_val_score(lm,X,y,cv=10,scoring='neg_mean_squared_error'))
socre结果为:0.047206999550184515
还是cv=5的评估会好一点。接下来我们cv都用5。
第二次
我们用建立一个PetalLengthCm和SepalLengthCm作为自变量X、PetalWidthCm作为因变量y的回归模型,看看它的性能。
lm = linear_model.LinearRegression() features = ['PetalLengthCm','SepalLengthCm'] X = iris[features] y = iris['PetalWidthCm'] model = lm.fit(X,y) score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error')) print(score)
socre结果为:0.0460189525758
第三次
我们用建立一个PetalLengthCm、SepalLengthCm和SepalWidthCm作为自变量X、PetalWidthCm作为因变量y的回归模型,看看它的性能。
lm = linear_model.LinearRegression() features = ['PetalLengthCm','SepalLengthCm','SepalWidthCm'] X = iris[features] y = iris['PetalWidthCm'] model = lm.fit(X,y) score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error')) print(score)
socre结果为:0.0395036603861
通过这三次的性能评估,我们可以看出来第二次用PetalLengthCm和进行拟合,效果并没有比第一次好太多,基本可以忽略。但第三次就明细比第一第二次好很多。主要是因为SepalLengthCm和SepalWidthCm之间是存在关系,他们共同的作用对PetalWidthCm的有明显影响。
这种性能评估方法,如果变量很多,需要进行很多次,当然也可以同程序自动化去做。
下面我们进一步自动化,把所有特征自动组合计算得分。
我们先定义一个combinations函数,它的作用是把特征的所有组合找出来。
def combinations(ls):
n=1<<len(ls)
tmp=[]
for i in range(n):
bits=[i>>offset&1 for offset in range(len(ls)-1,-1,-1)]
if numpy.sum(bits)>0:
current=[ls[index] for (index,bit) in enumerate(bits) if bit==1]
#print(current);
#print([tmp,current])
tmp= tmp+[current]
return tmp
我们让group等于所有的特征,通过把特征的所有组合提取出来。
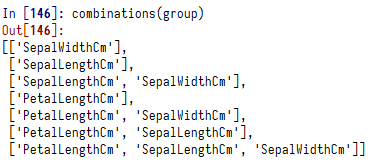
group=['PetalLengthCm', 'SepalLengthCm', 'SepalWidthCm'] group_combinations = combinations(group)
结果如下:
接下来我们对这个特征组合进行循环,在循环里面再对模型进行得分,并输出结果。
cv=5 #定义样本分组的大小
for v in group_combinations:
X = iris[v]
y = iris['PetalWidthCm']
model = lm.fit(X,y)
score = numpy.mean(-cross_val_score(lm,X,y,cv=cv,scoring='neg_mean_squared_error'))
print('特征'+str(v) +'的平均得分:'+ '%.4f' % score)
结果如下:
- 特征[‘SepalWidthCm’]的平均得分:0.7661
- 特征[‘SepalLengthCm’]的平均得分:0.2436
- 特征[‘SepalLengthCm’, ‘SepalWidthCm’]的平均得分:0.1917
- 特征[‘PetalLengthCm’]的平均得分:0.0455
- 特征[‘PetalLengthCm’, ‘SepalWidthCm’]的平均得分:0.0443
- 特征[‘PetalLengthCm’, ‘SepalLengthCm’]的平均得分:0.0460
- 特征[‘PetalLengthCm’, ‘SepalLengthCm’, ‘SepalWidthCm’]的平均得分:0.0395
可以看出,还是选择全部的特征的模型的得分低,即预测性能最好。所以如何选择特征值,反而是比较困难的工作,这个和业务的熟悉程度、专业度等都非常相关。以后我会继续和大家分享有什么好的办法去选择或者构造合适的特征值。
最后提供sklearn的的一些返回值参考。
model.predict([[5,6,3]]) model.score(X,y)
具体请参考 https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
from sklearn import linear_model
import pandas
import seaborn as sns
from sklearn.model_selection import cross_val_score
import numpy
from itertools import combinations
iris = pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']
sns.regplot(x='PetalLengthCm',y='PetalWidthCm',data=iris)
lm = linear_model.LinearRegression()
features = ['PetalLengthCm']
X = iris[features]
y = iris['PetalWidthCm']
model = lm.fit(X,y)
score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error'))
print('平均性能得分:'+str(score))
print('截距:'+str(model.intercept_),'特征系数:',model.coef_)
lm = linear_model.LinearRegression()
features = ['PetalLengthCm','SepalLengthCm']
X = iris[features]
y = iris['PetalWidthCm']
model = lm.fit(X,y)
score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error'))
print('平均性能得分:'+str(score))
print('截距:'+str(model.intercept_),'特征系数:',model.coef_)
lm = linear_model.LinearRegression()
features = ['PetalLengthCm','SepalLengthCm','SepalWidthCm']
X = iris[features]
y = iris['PetalWidthCm']
model = lm.fit(X,y)
score = numpy.mean(-cross_val_score(lm,X,y,cv=5,scoring='neg_mean_squared_error'))
print('平均性能得分:'+str(score))
print('截距:'+str(model.intercept_),'特征系数:',model.coef_)
def combinations(ls):
n=1<<len(ls)
tmp=[]
for i in range(n):
bits=[i>>offset&1 for offset in range(len(ls)-1,-1,-1)]
if numpy.sum(bits)>0:
current=[ls[index] for (index,bit) in enumerate(bits) if bit==1]
tmp= tmp+[current]
return tmp
cv=5
group = ['PetalLengthCm', 'SepalLengthCm', 'SepalWidthCm']
group_combinations = combinations(group)
for v in group_combinations:
X = iris[v]
y = iris['PetalWidthCm']
model = lm.fit(X,y)
score = numpy.mean(-cross_val_score(lm,X,y,cv=cv,scoring='neg_mean_squared_error'))
print('特征'+str(v) +'的平均得分:'+ '%.4f' % score)

